Warum mache ich aus Webseiten Bücher?
Auf den Webseiten mit Wander- oder Paddelbeschreibungen biete ich ganz oben das Herunterladen eines PDFs an. Beim Klick auf den blauen Knopf lädt der Browser ein PDF herunter, welches die Webseite ausgedruckt im A5 Format enthält. Warum biete ich das an?
Download dieser Seite als .pdf
1.) Als Wanderlektüre abseits des Netzes
Ich hatte damit begonnen, weil ich für das Lesen draußen in der Wildnis etwas anbieten wollte, das ohne Internet funktioniert. Die Beschreibung einer 4-wöchigen Alpenüberquerung nimmt bei mir über 100 MByte in Anspruch. Ein einziger Aufruf dieser Webseite kann bei sparsamen Menschen wie mir schon einen erheblichen Anteil des monatlichen Datenvolumens verbrauchen!
Das Große an der Webseite sind die Bilder. Sie sind nur so weit komprimiert, daß sie auch auf einem 4K-Monitor noch einigermaßen detailreich daherkommen. Auf einem 4K-Smartphone z.B. von Sony mit 6,5" Diagonale erschließt sich der Detailreichtum vermutlich nur mit einer Lupe, die man hoffentlich beim Kauf gleich mit dazu bekommt :-).
In den für Ebook-Reader und kleine Handys optimierten PDFs werden Fotos zu briefmarkengroßen Ausmaßen geschrumpft und verbrauchen kaum noch Platz. Dadurch sind die PDFs für ein Zwanzigstel der Datengröße der Webseite zu haben. Klar muß man sie vorher im WLAN von der Seite der jeweiligen Tour herunterladen, wo natürlich, bis ich den Knopf gedrückt habe, die vollen 100 MByte anfallen oder man lädt sie unterwegs von dieser Seite weiter unten.
Für das volle Lesevergnügen am großformatigen Monitor empfehle ich weiterhin die Webseite. Oder man druckt sich die Webseite selber nochmal in größerem Format aus, und liest die. Dabei geht nur die Interaktivität der Panoramen verloren.
2.) Weil es einfach ist und ich es kann
Das Umwandeln von Webseiten in Bücher ist recht einfach zu erledigen. Hier habe ich mal aufgeschrieben, was es zu beachten gibt und wie ich dabei vorgehe. Letztlich nutze ich nur die Druckfunktion des Browsers.
Der Extra-Aufwand für das Buch beschränkt sich darauf, ein hochformatiges Bild auszusuchen, welches sich als Titelbild eignet, und ein wenig Text für Titel und Vorspann-Seiten zu schreiben. Bücher ohne Titelbild machen sich ganz schlecht in den Galerien von Ebook-Readern. Das Inhaltsverzeichnis, was ebenfalls in jedes Buch gehört, erzeuge ich mit einem kurzen Perl-Script aus den H2-Überschriften.
Bilder mit den zugehörigen Bildunterschriften sind für bessere Lesbarkeit durch Suchmaschinen ohnehin schon in Figure-Elemente eingepackt, die Browser kaum noch auseinanderreißen. Im CSS setze ich explizit noch Verbote für Zeilenumbrüche in solchen Strukturen mit break-inside und page-break-inside. Weil ich nicht weiß, was die Browser wann unterstützen, gebe ich im CSS beide Formen an. Nach dem Buchvorspann setze ich einen Seitenumbruch, indem ich dem Container des Vorspanns im CSS die Eigenschaft page-break-after: page; mitgebe. Für den Druck auf Papier war's das schon: Ausdrucken mit dem Lieblingsbrowser, fertig.
Wenn ich in PDFs statt auf Papier drucke, muß ich noch einige Besonderheiten beachten. Ich bin momentan auf bestimmte Kombination Browser - Druckertreiber festgelegt, weil ich es nur damit schaffe, das Inhaltsverzeichnis mit funktionierender Verlinkung innerhalb des PDFs zu erzeugen. Außerdem muß ich die Bilder schrumpfen und die Informationen zu Autor, Buchtitel und Copyright händisch in die PDFs übertragen. Die Details stehen alle in dem Link oben.
3.) Als Absicherung gegen das Vergessen werden
Das World Wide Web ist sehr schnellebig. Vor 30 Jahren war es noch nicht da. Wo wird es in weiteren 30 Jahren sein? Wird man da meine Wanderberichte noch finden? Oder in 100 Jahren?
Andererseits sind Wanderberichte relativ zeitlos. Die Verkehrsmittel ändern sich, aber zu Fuß gewandert wird immer noch in Schuhen. Auch Bücher überdauern vermutlich die Zeiten besser als Webseiten. Ich kann zum Beispiel ein Buch von Dr. Eugen Bolleter "Bilder und Studien von einer Reise nach den Kanarischen Inseln" auch heute noch mit Vergnügen lesen. Das Buch ist 1910 erschienen. Die Webseite, von der ich es vor 20 Jahren heruntergeladen habe, gibt es noch: www.biolib.de, auch wenn sie mit der Zeit nicht gut mitgehalten hat. Die Seite bietet keine verschlüsselte Verbindung und das Impressum wurde letztmalig 2006 geändert. Die Webseite wird vom Max-Planck-Institut am Leben erhalten.
Auf so eine Unterstützung kann ich nicht hoffen. Ich kann meine Webseiten bei Archive.org archivieren, in der Hoffnung, daß die auch in Zukunft noch den Plattenplatz haben, um alles zu speichern. Aber wer wird mich dort suchen?
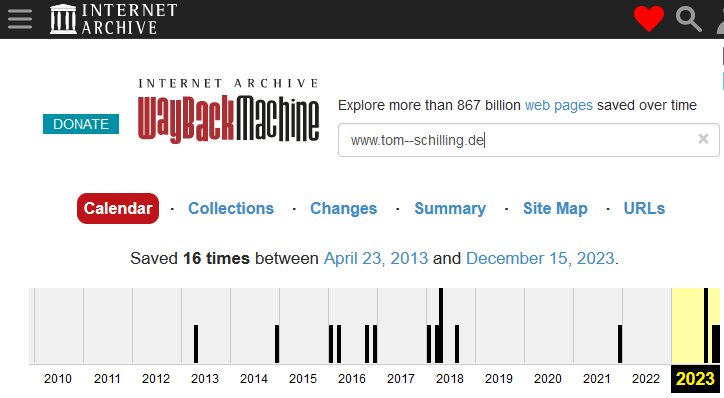
Neu erstellte Seiten melde ich seit 2023 bei Archive.org an. Dafür genügt ein Klick auf die Browsererweiterung. Ich staune selber, wie die Schnappschüsse ab 2013 zustande gekommen sind. Ich war das nicht!
Warum wird meine Webseite demnächst verschwinden?
Auf den Betreiber einer Webseite kommen immer neue Hürden zu. Mal nur die Highlights der letzten Jahre:
- Mein Webspace-Provider ist in den letzten 20 Jahren dreimal von einem anderen geschluckt worden. Jedes Mal ändern sich die Prozeduren für den Datei-Upload und den Austausch der Sicherheitszertifikate.
- Auf Googles Initiative hin sollen alle Webseiten nur noch HTTPS-verschlüsselt zu erreichen sein. Das ist sinnvoll, um Manipulationen auf dem Transportweg zu erschweren. Seiten ohne Verschlüsselung bestraft Google mit einem Ranking unter "ferner liefen". Also muß ich da mitmachen, auch wenn es sich vermutlich nicht lohnt, in meinen Datenstrom Schadcode einzuschleusen. Ich liefere meine Seite als https all denen aus, die Verschlüsselung anfordern, schließe allerdings Nutzer nostalgischer Browser (wie auf dem Amiga) nicht aus, die kein https haben.
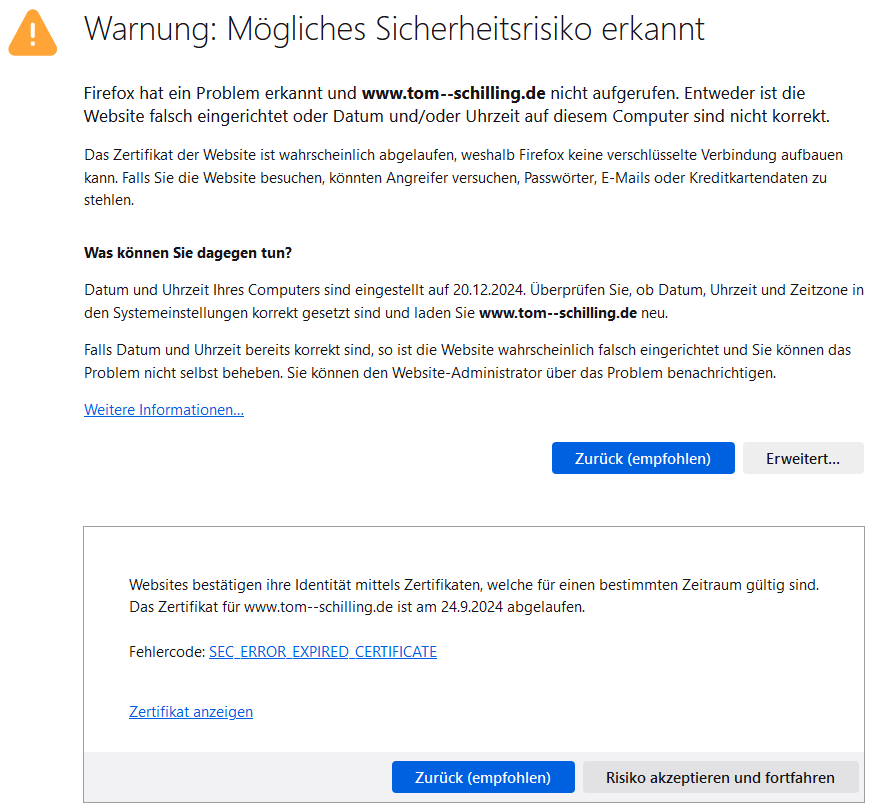
Der Haken an der Sache: Bei meinem Webspace-Provider kann ich zwar durch ein gefülltes Bankkonto dafür sorgen, daß die Webseite unbegrenzt lange gehostet wird, aber um die jährliche Erneuerung der Zertifikate muß ich mich selber kümmern. Wenn ich das mal nicht mehr kann oder das vergesse, bekommt der Besucher meiner Webseite so was zu sehen wie im Bild unten. Na, wer traut sich, auf "Erweitert" zu klicken und dann auf "Risiko akzeptieren und fortfahren"?
Die einfache Lösung wäre übrigens, die Seite über ein vorangestelltes http:// statt https:// aufzurufen.
(Die Fehlermeldung habe ich erzeugt, indem ich die Uhr ein Jahr vorgedreht habe. In der Realität kommt im Fall eines abgelaufenen Zertifikats ein anderer Text, denn aktuell erkennt Firefox natürlich, das nur meine Uhr im Computer falsch geht.)
- Die Impressumspflicht kam kurz nach der aus Datenschutzgründen getroffenen Entscheidung, daß nicht mehr jedermann Name und Adresse des Domaininhabers mit whois abfragen darf. Jetzt soll jedermann die aus dem Impressum lesen. Verrückte Welt.
Glücklicherweise betrifft mich das nicht, denn ich mache mit meiner Webseite keinen Umsatz. Kontaktieren kann man mich über die auf jeder Webseite im Menü ganz unten angegebene Emailadresse. Zum selber abschreiben, damit sie nicht von einem Spam-Bot ausgelesen werden kann. Erwartet bitte keinen 7/24-Service, denn manchmal bin ich offline unterwegs. - Die Datenschutz-Grundverordnung DSGVO erforderte, daß jeder auf seiner Webseite eine Einwilligung zum Setzen von Cookies und Verarbeiten personenbezogener Daten holt. Auch das betrifft mich nicht, denn ich setzte keine Cookies und erhebe keine Daten.
- Bei all diesen Entscheidungen haben die Interessen des kleinen Hobby-Bloggers wohl nicht im Mittelpunkt gestanden. Die nächste Änderung könnte ihm vollends den Garaus machen: die eIDAS-Verordnung der EU. Die c't 29-2023 hat eine Artikelserie zu den Hintergründen und auch bei Fefe findet sich was.
Die Zertifikate für Webseiten sollen nicht mehr von privatwirtschaftlichen Firmen, sondern von staatlichen Stellen signiert werden. Statt wie bisher nur den Besitz von www.tom--schilling.de durch mich zu bestätigen, sollen gleich noch eine Menge anderer Daten eingesammelt und validiert werden, darunter Namen und Adresse. Die sollen dem Internetbenutzer beim Klick auf das Verschlüsselungssymbol angezeigt werden und ihm ein gutes Gefühl von Sicherheit geben. Mit dem Verifizieren dieser Daten läßt sich viel Geld verdienen, weshalb die entsprechenden Zertifikate für Privatnutzer unerschwinglich werden könnten.
Mal abgesehen davon, daß ich als Blogger auch ein Recht auf Datenschutz habe und diese Daten nicht in die Welt hinausposaunen will. Sorry Fans, heute verbringe ich den Abend lieber allein. :-)
Klar sieht die Verordnung erst mal nur vor, daß die Browserhersteller solche Zertifikate in ihre Produkte einbauen sollen und Zertifizierungsstellen entstehen. Und die Beschränkung auf Europa könnte suggerieren, daß es irgendwo noch einen freien Rest der Welt gibt, der da nicht mitzieht. Da würde ich mir keine Hoffnung machen, beim Sammeln von Daten und der Überwachung von Bürgern (den hauptsächlichen Bedenken der Kritiker) sind die Amis schnell mit dabei. Und die Einführung von HTTPS hat uns gelehrt, daß es Ruckzuck keine Alternativen mehr gibt. - Im April 2025 hat die Allianz der Zertifikats-Herausgeber und Browser-Hersteller (CA/B)beschlossen, daß Zertifikate demnächst nur noch eine Gültigkeit von 47 Tagen haben werden. Bisher wurde ich jedes Jahr einen Monat vor Ablauf des Zertifikats per Mail informiert und mußte im Kundenportal ein neues bestellen. Längere Touren kann ich in der Zeit nicht unternehmen, denn ich habe das Portal noch nie von einem Reisehandy (stromsparend und leistungsschwach) aufgerufen. Ich habe auch keine Lust, mich jeden Monat erneut mit dem Thema zu beschäftigen. Deshalb bin ich zu einem Webspace-Provider gewechselt, der sich um die Zertifikats-Ausstellung komplett selber kümmert.
⇒ Eine Webseite überlebt heutzutage ohne Betreuung kein halbes Jahr! Auch wenn ich heute noch putzmunter draußen rumkraxel, irgendwann ist Schluß damit, vermutlich eher früher als später. Demenz oder Tod, das ist hier die Frage.
Was hat das nun alles mit Büchern zu tun?
Soweit die Vorrede.
Es gibt noch ein anderes Gesetz, das sich mit Medien-Inhalten beschäftigt, die Verordnung über die Pflichtablieferung von Medienwerken an die Deutsche Nationalbibliothek (PflAV). Darin steht, daß von jedem Medienwerk, auch elektronischen, ein Exemplar in die Sammlung der Deutschen Nationalbibliothek gehen soll. Prima! So sind aus meinen 17 Wanderwebseiten 17 Bücher geworden, die in einem offiziellen Katalog verzeichnet sind. Zuständige Sammelstelle für mich als Sachsen ist der Katalog der SLUB, der "Sächsischen Landesbibliothek - Staats- und Universitätsbibliothek Dresden".
(Im Link der SLUB: "Erweiterte Suche" mit Autor: Tom Schilling und Verlag/Ort: Dresden)
Von da aus werden sie manuell in den Katalog der Nationalbibliothek weitergegeben. Der Nationalbibliothek traue ich irgendwie einen längeren Atem zu, als privat betriebenen Internetseiten inklusive meiner eigenen oder Archive.org.
Alle Bücher sind im Open Access auch bei Qucosa veröffentlicht, das ist ein Publikationsserver, der sich hauptsächlich mit wissenschaftlichen Veröffentlichungen beschäftigt. Aber er sammelt auch allgemein Bücher und wer sagt denn, daß meine Langstreckenwanderungen nicht als Forschungsreisen durchgehen? ;-)
4.) Um meine Reichweite zu erhöhen
Natürlich habe ich die Hoffnung, daß mir die Buchveröffentlichungen zusätzliche Backlinks einbringen, ich dadurch höher ranke und mehr Leser anspreche. Bislang ist dieser Effekt leider noch nicht bemerkbar, weil Google vermutlich die Kataloge der Bibliotheken nicht durchsuchen darf.
Liste meiner Wanderbücher
Wenn ich mir die Tabelle so ansehe, fällt mir auf, daß ich die Buchtitel etwas systematischer hätte wählen können. Na, das korrigiere ich dann bei den Prachtausgaben, nachdem ich alle Reiseberichte fertig aufgeschrieben habe. :-)